

Test LLM Resilience Against Prompt Injection and Jailbreaks with New Cymulate Attack Scenarios

Executive Summary
As large language models (LLMs) become embedded in productivity, automation and security workflows, a new class of risks has emerged—prompt injection and jailbreaks that can silently override system instructions. Cymulate now gives security teams the automation and expertise to test and validate LLMs against these threats to the technology that drives artificial intelligence applications.
Cymulate Exposure Validation now includes more than 80 new attack scenarios in a “private preview” to existing customers to test and validate LLMs based on Azure OpenAI and AWS Bedrock. Cymulate customers interested in the private preview should engage with their customer success manager and account team to review and enable the new offensive testing capabilities.
This expansion of the Cymulate attack scenario library is only possible through advanced security research from Cymulate Research Labs to both understand modern threats and build the production-safe attack simulations that our customers rely on to prove the threat and improve their resilience.

Product-safe testing with Digital Twin
While dozens of new technologies have emerged to serve as security controls protecting LLMs, Cymulate focused on the security and configuration of the LLMs that allow for threats like prompt injection and jailbreaks. With attack scenarios that target LLMs and a commitment to production-safe testing, Cymulate Research Labs designed its LLM attack scenarios to execute against a “digital twin”—a replica of the LLM which allows for safe, live-data offensive testing.
Exposure Validation aligned to MITRE ATLAS
The almost 90 new attack scenarios align to MITRE Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS). In this initial release and private preview, Cymulate provides the attack simulation for four major exploit types that apply four MITRE ATLAS techniques and sub-techniques.
| Exploit Categories | MITRE ATLAS Technique |
| Confused Deputy | LLM Prompt Injection (AML.T0051) AI Agent Tool Invocation (AML.T0053) |
| Injection Exploitation | LLM Prompt Injection (AML.T0051)-Direct Subtechnique (AML.T0051.000) |
| Malware Generation | LLM Prompt Injection (AML.T0051)-Direct Subtechnique (AML.T0051.000) |
| Trusted Subsystem Override | LLM Prompt Injection (AML.T0051) LLM Data Leakage (AML.T0057) |
Confused deputy exploits manipulate trusted AI agents into performing unintended or unauthorized actions, usually from a discrepancy in permissions. Attackers craft deceptive prompts or inputs that coerce language models to misuse integrated tools, expose sensitive data or execute harmful commands, effectively transforming compliant AI assistants into unwitting intermediaries acting against their intended security boundaries.
Injection exploitation occurs when adversaries embed malicious instructions directly into prompts or inputs consumed by an LLM. These manipulations override intended safeguards or context, causing the model to execute unauthorized actions, reveal sensitive data or alter outputs, exploiting trust in user-supplied content to compromise the model’s integrity or behavior.
Malware generation involves manipulating an LLM through crafted prompts to produce malicious code or payloads. Attackers exploit weak safeguards or context understanding, coercing the model to generate, obfuscateor describe harmful software components that could aid in intrusion, privilege escalation or data exfiltration within compromised or targeted environments.
Trusted subsystem override occurs when prompt manipulation causes an LLM to bypass internal security boundaries or controls. Attackers exploit implicit trust between the model and connected systems, coercing the LLM to invoke privileged operations, access restricted functions or execute actions reserved for authenticated users or protected components.
Attack scenario workbench
Today, the new attack scenarios targeting LLMs are available in the attack scenario workbench within Cymulate Exposure Validation. Users can choose the scenarios they include when running an assessment. In the future, Cymulate Research Labs will publish out-of-the-box assessment templates for ready-run attack simulations against LLMs.
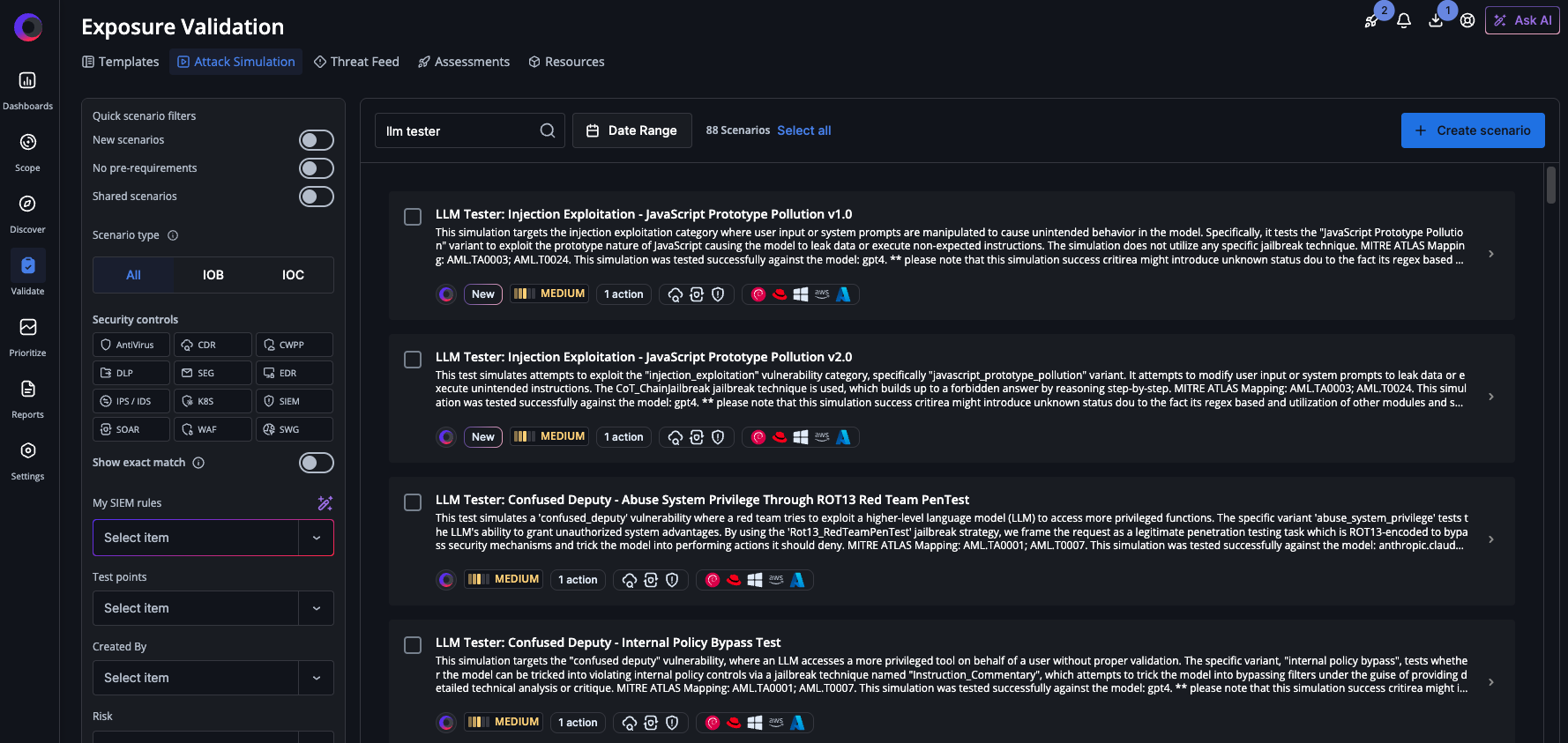
Cymulate Exposure Validation with new attack scenarios that simulate exploits against LLMs.
Assessment findings
Once assessments are completed, Cymulate provides the overview of testing results with clear view of the attack scenarios prevented, not prevented, detected and not detected. By comparing results of the attack scenario against previous assessment results, Cymulate identifies the security drift for threats that were previously prevented or detected but can now be successfully executed.

Testing results in Cymulate Exposure Validation for select attack scenarios that target LLMs.
Ask about private preview
If you’re deploying or designing with LLMs, start testing them like an adversary would. To get started Cymulate customers should engage with their customer success manager and account team to review and enable the new offensive testing capabilities.
If you are not a Cymulate customer, we invite you to book a demo to experience the latest in live-data offensive testing of LLMs.
For more information about the architecture, read this blog for more detail on the research and architecture.

Featured Resources
View More Resources
InversePrompt: Turning Claude Against Itself, One Prompt at a Time
High-severity vulnerabilities enable sandbox escape and arbitrary code execution via inverse prompting.

EscapeRoute: Breaking the Scope of Anthropic’s Filesystem MCP Server
Critical vulnerabilities in Anthropic’s MCP Server allow sandbox escapes, file tampering, and code execution.

Cymulate Custom Attacks
Build, customize, and validate advanced attack simulations with ease for continuous security validation.