

Data Drift Detection

Drift Detection Explained: How to Identify and Prevent Data Drift
Data drift can silently erode the performance of AI and ML systems, leaving organizations vulnerable to undetected threats. In cybersecurity, machine learning (ML), and artificial intelligence (AI) domains, maintaining system performance is a critical priority.
A significant challenge to achieving this lies in detecting and mitigating data drift—a phenomenon where changes in data distributions compromise the reliability and accuracy of models.
With increasing reliance on automation to secure assets, drift detection has become indispensable for IT security teams, DevOps engineers, security analysts, and CISOs. By identifying and addressing this hidden threat, teams can make sure the resilience of their systems against dynamic data environments and adversaries.
What is Data Drift?
Data drift refers to changes in the statistical properties of input data over time, which can impact the performance of ML models, automated systems, and cybersecurity frameworks. There are two primary types of data drift:
- Concept Drift: Occurs when the relationship between input data and the target variable changes. For instance, a fraud detection system trained on past transaction patterns may struggle to identify new fraudulent behaviors.
- Feature Drift: Happens when the distribution of individual input features changes without altering the underlying relationship to the target variable. For example, a change in user demographics could skew feature importance in an ML model.
Data drift can pose serious risks to security operations, as static models become ineffective in detecting or mitigating new threats.
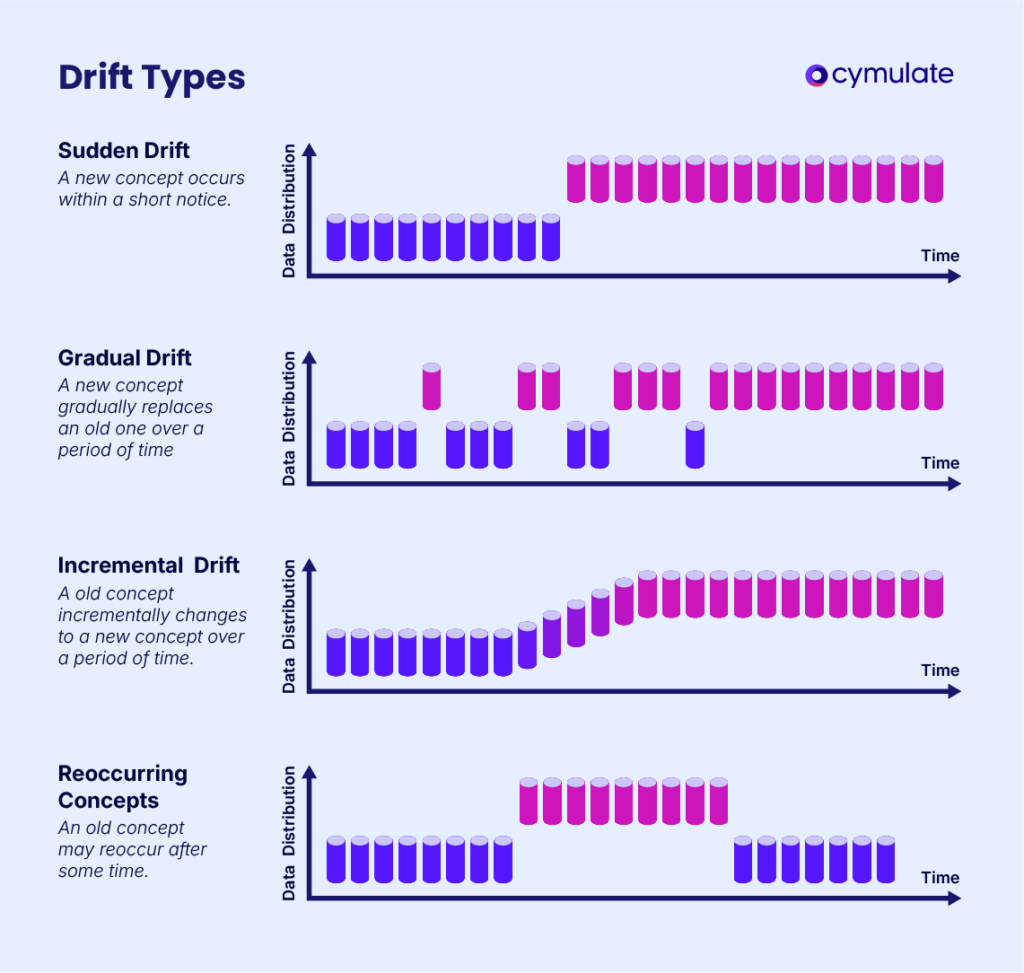
For security teams relying on automation, identifying and addressing drift is essential to ensure continued protection against sophisticated adversaries.
This phenomenon can also impact industries outside cybersecurity, from finance to healthcare, where predictive models need to keep pace with real-world changes.
How Does Drift Occur?
Drift arises from several factors, many of which reflect the dynamic nature of real-world conditions. Common causes include:
Developing real-world conditions
As user behavior, external environments, or operational contexts change, input data may no longer align with the assumptions underpinning your ML or AI models.
For example, changes in attack techniques could invalidate threat detection algorithms. The shifting nature of adversarial strategies, such as new malware variants or phishing tactics, demands that systems adapt swiftly to retain their effectiveness.
Outdated models
Static models that fail to adapt to dynamic data environments are highly susceptible to drift. Without regular updates or retraining, these models become less accurate and less effective at identifying anomalies.
Even models designed for long-term use must be evaluated periodically to ensure they remain relevant to current data trends.
Bias in training data
Skewed or incomplete datasets can introduce inaccuracies, leading to unforeseen performance degradation over time.
For instance, security systems trained exclusively on historical attack patterns may overlook new vulnerabilities or tactics used by adversaries. Addressing such biases early in the model development phase can help reduce drift risks in production environments.
Drift Detection Techniques
Proactively detecting drift is key to maintaining system integrity and performance. Several methodologies help identify data drift effectively:
Statistical techniques
Metrics like Kullback-Leibler divergence, Jensen-Shannon divergence, or Kolmogorov-Smirnov tests are commonly used to detect changes in data distributions.
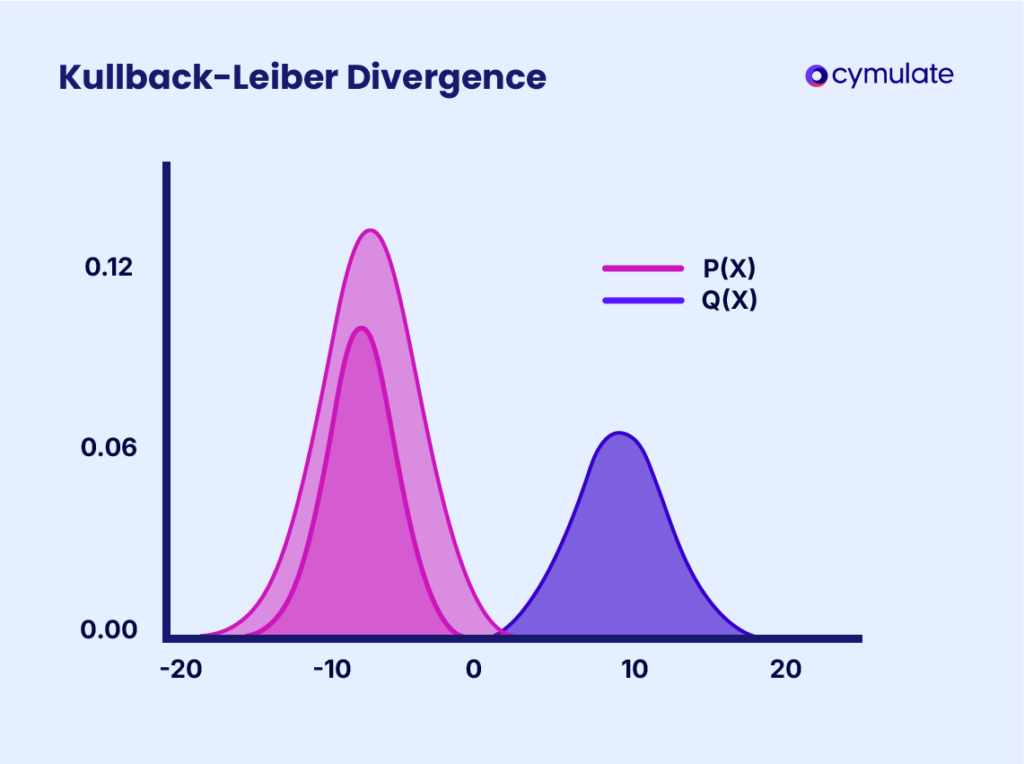
These techniques provide quantitative insights into how far the current data deviates from historical baselines. They are particularly effective when implemented in real-time monitoring tools that flag deviations as soon as they occur.
Baseline comparisons
Monitoring deviations from established baselines—whether through statistical thresholds or manual evaluation—can help flag instances of drift.
For example, a sudden spike in anomaly rates could signal feature drift. These baselines should be periodically recalibrated to account for natural variations in data over time.
Performance monitoring
Tracking performance metrics such as accuracy, precision, or recall over time can serve as indicators of drift. A consistent drop in these metrics suggests that the model’s predictive capabilities are being undermined.
Combining performance monitoring with statistical techniques provides a comprehensive approach to drift detection.
Tools for drift detection
Numerous tools support automated drift detection, including ML monitoring platforms and cybersecurity validation systems.
These solutions integrate statistical techniques, performance monitoring, and real-time alerts to ensure early identification of drift. Examples include platforms like Evidently AI and Arize AI, which specialize in tracking ML model performance and identifying distribution changes.
Concept drift analysis
Concept drift analysis specifically targets changes in the relationship between input features and target variables.
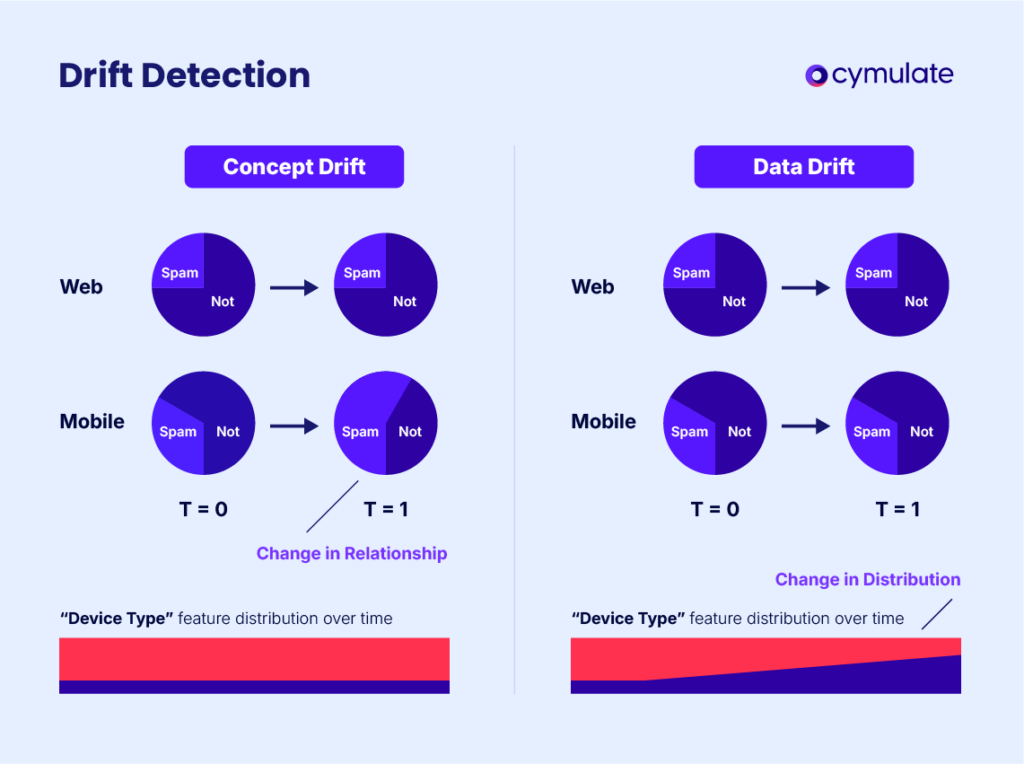
This method identifies shifts in how certain input data contributes to predictions, which is particularly critical for systems where relationships evolve over time.
By modeling expected dependencies, concept drift analysis can pinpoint deviations that might otherwise go unnoticed.
Ensemble model monitoring
Using ensemble models for drift detection involves comparing the outputs of multiple models trained on different versions of the data.
Discrepancies in their predictions can indicate potential drift. This approach is particularly valuable in scenarios where continuous data updates are impractical, as it offers a comparison across varying data conditions.
How Do You Prevent Data Drift?
While detection is crucial, prevention strategies play an equally vital role in mitigating the impact of drift. Here are actionable approaches:
Continuous monitoring
Implement regular validation cycles to assess both model and system performance. Tools that offer real-time monitoring ensure that potential drift is identified and addressed promptly. This approach minimizes the risk of prolonged exposure to vulnerabilities caused by undetected drift.
Data validation pipelines
High-quality and up-to-date data inputs are foundational to reducing drift. Automated pipelines can flag inconsistent or outdated data, preserving the integrity of inputs.
These pipelines can also include preprocessing steps to normalize data and eliminate biases before they affect model performance.
Model retraining
Periodic retraining using fresh datasets ensures that models remain aligned with evolving data distributions. Retraining schedules should be based on the model’s criticality and observed drift patterns.
Frequent retraining is especially important for systems operating in high-stakes environments, such as financial fraud detection or healthcare diagnostics.
Security control testing
Cybersecurity frameworks must improve alongside newer and many technical threats. Adaptive security controls, validated through continuous testing, can preempt the weaknesses introduced by drift.
Regular penetration testing and red teaming exercises complement drift prevention efforts by uncovering gaps in security postures.
Regular feedback loops
Using feedback loops between your deployed models and their development environments can provide valuable insights into the changes in data distributions.
These loops allow teams to identify trends and proactively address potential drift before it impacts model performance.
Diversified training data
Incorporating diverse and representative data during the training phase minimizes the risk of drift. By including varied scenarios and conditions, models can better generalize and remain robust in dynamic environments.
By modeling expected dependencies, concept drift analysis can pinpoint deviations that might otherwise go unnoticed.
Cymulate and Drift Detection
The Cymulate Continuous Security Validation platform empowers organizations to detect and mitigate the challenges associated with data drift.
By simulating real-world attack scenarios and validating security controls, Cymulate provides actionable insights to help security teams stay ahead of evolving threats.
- Continuous validation: Cymulate continuously validates security controls, identifying weaknesses caused by outdated assumptions or changes in attack vectors. This proactive approach allows systems to remain resilient even as external conditions shift. Through automated simulations, organizations can test their readiness against both known and emerging threats.
- Drift detection in threat models: By analyzing threat models and attack techniques, Cymulate identifies instances of drift that could compromise the effectiveness of cybersecurity frameworks. For example, emerging attack patterns are flagged and incorporated into validation tests. This ensures that security protocols remain effective against a constantly evolving threat landscape.
- Actionable recommendations: Through tailored recommendations, Cymulate guides organizations in retraining models, updating security protocols, and enhancing system configurations to address drift. These insights help security teams maintain robust defenses against dynamic threats. Cymulate’s platform also integrates seamlessly with existing security ecosystems, making it easier for teams to implement changes without significant operational disruptions.
To Conclude
Drift detection is necessary in cybersecurity to make sure that machine learning and AI systems maintain performance while adapting to evolving environments.
By understanding the causes and implementing proper detection and prevention strategies, organizations can protect and potentially secure their systems from vulnerabilities introduced by dynamic data environments.
With Cymulate’s expertise in continuous validation and exposure management, businesses can stay resilient in the face of such technical threats.
Featured Resources
View More Resources
Measure and Baseline Cyber Resilience
Use Cymulate to assess baseline cyber resilience, uncover weaknesses, and improve your organization’s security posture.
5 Game-Changing Tips for CISO Success
As business pressures increase, chief information security officers (CISOs) face an alarming disconnect from executive teams. WSJ recently published research

Law Enforcement Agency Restores Confidence in Cyber Defenses
This small cybersecurity team is tasked with protecting the organization’s fraud services and all electronic records related to criminal investigations.