

Common Vulnerabilities and Exposures (CVE)
CVE vs. CVSS: Decoding Severity Scores and Prioritizing Exploitable Threats
A CVE is a standardized identifier assigned to a publicly known software or hardware vulnerability. Think of a CVE as a unique label (like a serial number) for a specific security flaw.
This common naming makes it easy for security teams to tag, share and compare vulnerability information across tools and organizations. By using CVE identifiers, vulnerability management programs can consistently track known weaknesses and prioritize fixes.
In short, CVEs provide a common language for risk management: they tell everyone exactly which vulnerability is under discussion, and help teams focus on patching and mitigation in a consistent way.
Each CVE entry includes an identifier (formatted like CVE-2023-12345), a brief description of the issue, and references to technical details or patches.
As an example, CVE-2021-44228 refers to a critical remote code execution bug in the Apache Log4j logging library (the infamous “Log4Shell”). By providing a stable identifier for the vulnerability, security analysts can coordinate their response (testing patches, scanning for the issue, etc.) without confusion.
What Are Common Vulnerabilities and Exposures (CVE)?
CVE stands for Common Vulnerabilities and Exposures. It is not a metric or a score, but a standard ID string for a security issue. In other words, the CVE program provides a public “dictionary” of vulnerability names so everyone can speak the same language. For each new vulnerability that meets its criteria, MITRE (the organization maintaining CVE) creates a record with a unique ID.
This ID follows the format “CVE-YYYY-NNNN” (for example, CVE-2024-12345) where YYYY is the year and NNNN is a sequence number. The CVE record will have a short title and description, plus links to vendor advisories or technical references.
Officially, MITRE defines CVE as a dictionary or glossary of vulnerabilities, maintained in the public interest. MITRE sponsors the program (in partnership with government agencies like DHS/CISA) and works with hundreds of CVE Numbering Authorities (CNAs) worldwide. CNAs include major software vendors and research organizations (for example, IBM, Microsoft, Oracle, and numerous open-source projects).
When a new flaw is discovered, the reporter (often a security researcher or vendor) contacts the appropriate CNA, which assigns a CVE ID and writes up the official entry. In this way, MITRE and the CNAs ensure that each vulnerability has one and only one CVE ID, which prevents duplicate names and confusion across the security industry.
The CVE list is publicly available and free to use. It serves as the authoritative baseline for vulnerability information. For example, the U.S. National Vulnerability Database (NVD) and other vulnerability databases “feed” on the CVE list: NVD enriches each CVE entry with additional details like severity scores (CVSS), impact metrics, and fix information.
Security tools (scanners, SIEMs, patch managers) import CVE data so they can label detected flaws consistently. In short, a CVE ID uniquely identifies a known vulnerability, and tools can all refer to that same ID to coordinate analysis and remediation.
How Are CVEs Disclosed and Assigned?
The lifecycle of a CVE begins with discovery. When a security researcher, user, or software project identifies a flaw, they report it to a CVE Numbering Authority (CNA) or directly to MITRE. The report includes enough details to understand the issue (affected software, how it can be exploited, and any proof-of-concept information). The CNA then reserves a CVE ID for the vulnerability and starts working on the official entry.
Once a CVE ID is reserved, the CNA (or MITRE itself, acting as a CNA) will prepare the CVE record. This involves writing a concise description of the vulnerability, listing affected products, and providing references or links (for example, vendor advisories or patches). After review, the CVE entry is published to the central CVE list. At that point it is considered a public CVE.
In some cases, if the vulnerability does not meet the criteria or is not a true vulnerability, a CNA may mark a reserved CVE as REJECTED (meaning the identifier will not be used) or DISPUTED (if the validity of the issue is in question). Otherwise, a reserved CVE will typically be updated into a final entry once enough information is available.
In practical terms, here are the key steps in the CVE assignment process:
- Discovery and Reporting: An issue is found by a researcher, developer, or automated scanner and reported to the appropriate CNA or MITRE.
- Assignment: The CNA validates the report and assigns a CVE ID (e.g. CVE-2025-12345). The CVE is initially in a “RESERVED” state.
- Description and Publication: The CNA adds technical details and supporting references, then releases the CVE entry publicly. It enters the official CVE list (and is ingested by databases like NVD).
- Ongoing Management: If later information changes, the CVE entry can be updated (for example, to add new affected versions or patch links). The CVE record persists even after a fix is published, so teams can always refer back to the unique identifier.
After publication, the new CVE identifier becomes part of the public CVE list. Tools and teams use it to track and triage the vulnerability. For example, a vulnerability scanner might flag “CVE-2024-12345” on a server and use the CVE ID to look up detailed info.
Security analysts can see that CVE in their dashboards, apply a severity score (CVSS), and plan a patch. In this way, each CVE entry becomes the focal point for ongoing discussion and remediation of that specific issue.
Who Uses CVEs, and What For?
CVE identifiers are used by a wide range of cybersecurity roles and tools. Whenever an organization finds or fixes a vulnerability, it usually references the CVE ID to avoid ambiguity. Some examples of CVE usage include:
- Vulnerability Scanners: Tools like Nessus and Qualys tag flaws with CVE IDs, making it easy to match vulnerabilities across different platforms.
- Patch Management: Vendors include CVE IDs in patch notes, helping teams align updates with specific vulnerabilities.
- Threat Intelligence & SIEM: CVEs link threats to known exploits; SIEMs and IDS tools use them to tag and detect related events.
- Incident Response: Analysts use CVEs to filter logs, find exploit codeand understand attack details quickly.
- Compliance Reporting: Standards like PCI DSS and HIPAA reference CVEs to track unpatched vulnerabilities and assess risk.
CVSS Score and CVE Meaning
While CVE provides a unique identifier, the Common Vulnerability Scoring System (CVSS) provides a severity rating for that vulnerability. It is important to understand that CVE ≠ CVSS: one is a naming system, the other is a scoring system.
CVE is simply the ID (and description) of a known flaw. It tells you which vulnerability you have. For example, “CVE-2022-3602” refers to a particular OpenSSL bug. The CVE entry does not by itself indicate how bad the issue is or how likely it will be exploited.
CVSS is a numerical score (0.0 to 10.0) that estimates the severity of a vulnerability. CVSS was developed by FIRST (the Forum of Incident Response and Security Teams) and is used by NVD and many vendors to rate vulnerabilities. A higher CVSS score means the vulnerability is more severe or dangerous. For example, a CVSS score of 9.8 might indicate a critical remote code execution flaw, whereas a score of 2.1 would be a low-impact issue.
Each CVE entry in databases like NVD usually lists the CVSS Base Score for that vulnerability. The base score is calculated from two sets of metrics:
Exploitability Metrics
These gauge how easy it is to exploit the vulnerability. They include factors like Attack Vector (network vs local), Attack Complexity (is special conditions or user interaction needed?), Privileges Required, and User Interaction. For instance, a flaw exploitable over the internet without authentication (low attack complexity) will score higher on exploitability.
Impact Metrics
These measure the potential damage. Specifically, they assess the effect on Confidentiality, Integrity, and Availability (the CIA triad).
Each of those categories can be scored as None, Low, or High impact. A vulnerability that can fully compromise a system’s integrity and availability will get a high impact rating (and thus a higher CVSS).
CVSS defines Temporal and Environmental metric sets. Temporal metrics can adjust the score based on factors like whether exploit code is publicly available or a fix is already out. Environmental metrics allow an organization to modify the score for its specific context (for example, a vulnerability on a test server might be lower priority than the same CVE on a critical production system).
However, the Base Score (0-10) is the most commonly referenced number for each CVE, and is what appears in the CVE/NVD listing by default.
What Are the Most Common CVEs?
Over time, certain CVEs become infamous due to widespread exploitation. For example, CVE-2021-44228, nicknamed Log4Shell, is an Apache Log4j vulnerability that dominated news. It allowed attackers to submit a specially crafted request to vulnerable systems, causing them to execute arbitrary code.
In practice, Log4Shell gave threat actors full control of affected servers. As CISA noted, attackers could “take full control over the system,” stealing data or deploying ransomware. Because Log4j is embedded in thousands of products, this one CVE quickly became a global crisis.
Another headline example is CVE-2021-34527 (PrintNightmare). This was a critical flaw in the Windows Print Spooler service. It let an authenticated attacker run code with SYSTEM-level privileges on a Windows machine.
Exploit code for PrintNightmare emerged so fast that even fully patched systems could sometimes be bypassed. In short, PrintNightmare was essentially a remote code execution (RCE) issue: if a server had the vulnerable service enabled, attackers could exploit CVE-2021-34527 to gain a foothold as a system administrator.
Beyond those, many other CVEs see routine abuse by malware and criminals. For instance, the ProxyLogon and ProxyShell Exchange flaws (multiple CVEs in Microsoft Exchange) were heavily exploited in 2021, allowing attackers to run code on email servers. Vulnerabilities in Atlassian Confluence, VMware, and network equipment also frequently top the list of exploited CVEs.
Purpose of the CVE List
Why have a CVE list in the first place? The answer is standardization and coordination. Before CVE existed (pre-1999), each vendor or security company used its own names for vulnerabilities. One antivirus might call an issue “BufferOverflow-XYZ,” while another called it “BOF-123” – causing confusion. CVE solved this problem by giving each vulnerability a single, standardized name.
The CVE list serves as a universal dictionary of known vulnerabilities. This has several benefits:
- Interoperability: With CVEs, different tools and databases can exchange data without mismatch. For example, a vulnerability scanner, a patch management system, and a threat intelligence feed all referring to “CVE-2024-10001” will be talking about the exact same flaw.
- Coverage Baseline: CVE provides a baseline for evaluating security coverage. If a tool claims to scan for “all known vulnerabilities,” the CVE list defines what “known” means. Organizations can check whether their scanners or patch tools cover all CVEs relevant to their environment.
- Consistent Communication: When security researchers, vendors, and analysts refer to a CVE, everyone understands which vulnerability is meant. MITRE’s own handbook states that CVE identifiers “make it easier to share data across separate network security databases and tools”.
In effect, the CVE list is a global public registry of vulnerabilities. By using CVE IDs, the cybersecurity community maintains a common language. The list is free and publicly accessible, so anyone from a small startup to a government agency can use it as a reference.
This avoids duplicate efforts: instead of each team writing their own vulnerability catalog, they all rely on CVE as the authoritative source. All major vulnerability databases (like NVD) and security advisories around the world map back to the CVE list. This standardization is what allows cross-tool coordination and makes coordinated risk management possible.
CVE vs. CVSS
It’s important to clearly distinguish CVE from CVSS, as they often get mixed up.
| Aspect | CVE (Common Vulnerabilities and Exposures) | CVSS (Common Vulnerability Scoring System) |
|---|---|---|
| Purpose | Identification and cataloging of vulnerabilities | Scoring the severity of vulnerabilities |
| Format | CVE-ID (e.g., CVE-2023-12345) | Numeric score (0.0 to 10.0), with vector strings |
| Function | Names and tracks specific vulnerabilities | Helps prioritize vulnerabilities based on risk level |
| Data Source | Managed by MITRE and referenced in databases like NV | Often included alongside CVE in NVD or vendor advisories |
| Severity | Does not indicate severity | Indicates how critical a vulnerability is |
| Usage in Security Tools | Used to correlate vulnerabilities across scanners, advisories, and reports | Used to guide patch prioritization and risk assessment |
| Limitations | Doesn't reflect danger level or exploitability | Static score - should be used with context like exploitability and asset value |
| Relationship | CVE = the "name" of the flaw | CVSS = the "severity rating" of the flaw |
| Best Practice | Use CVE for tracking and CVSS as one of several inputs in risk management decisions | Combine CVSS with real-world threat intel and business impact context |
However, both CVE and CVSS have limitations. CVE itself says nothing about how dangerous a vulnerability is, and CVSS (even at its best) is just a starting point.
The Problem with CVE Scores
Given that CVSS scores are so widely used, it’s worth acknowledging their challenges. Many security pros have noted that relying solely on CVE IDs and CVSS scores can create blind spots or overload. Some common issues include:
1. Lack of Context
A CVSS score is static and based on generic metrics, not on your specific environment. For example, a “High” severity bug on a test server is less urgent than the same bug on a critical production system. CVSS does not capture such context by itself.
As one source points out, CVE entries and their scores “provide limited contextual information about how a vulnerability affects a specific environment”. Without additional analysis, teams may misprioritize vulnerabilities simply because of where they lie in the CVSS scale.
2. Static Scoring
CVSS base scores do not automatically update when new exploits appear or when patches are released. A vulnerability might get a high base score in theory, but if exploit code never materializes or effective mitigations are already in place, the actual risk can be lower.
Conversely, a medium-scored CVE with a new exploit in the wild could be more dangerous than its score implies. Newer CVSS versions (like v4.0) have tried to emphasize that the score should not be the sole factor in risk decisions.
3. Sheer Volume (Signal Overload)
The number of CVEs is enormous and growing. As of mid-2025, there were over 296,966 CVE records published, and the tally is rising by tens of thousands each year. (The NVD dashboard now shows roughly 297,000 CVEs in its database.)
No organization has the time or resources to address every CVE. This volume creates a “needle in a haystack” problem: how do you focus on the few issues that truly matter? Without smart filtering, teams can be overwhelmed by alerts about hundreds of high-severity CVEs, most of which might not actually impact their critical assets.
4. Inconsistencies
Because CVSS scoring involves some human judgment, scores can vary between analysts or vendors. Two different sources might rate the same CVE slightly differently. This can be confusing when trying to compare severity levels across platforms.
5. Timeliness and Accuracy
Some CVEs are only made public after a fix is available (a practice known as “reserving” the CVE until patch time). In these cases, organizations may not hear about the issue until late in the game, leaving systems exposed in the interim. Additionally, incomplete or inaccurate information in a CVE entry (or outdated CVSS data) can distort risk assessments.
As a result, many security experts say CVSS and the raw CVE list should not be blindly trusted as the only guide. For example, FIRST itself now emphasizes that “CVSS should not be solely relied upon for vulnerability prioritization”.
Instead, vulnerability management needs to incorporate actual threat intelligence, exploit data, and knowledge of the local environment. Otherwise, defenders risk chasing scores instead of the real risks.
Cconsider the following statistics from industry reports: on average 111 new vulnerabilities are disclosed every day, yet organizations patch only about 5% of their vulnerabilities each month.
It’s no wonder attackers have the advantage. We hear repeatedly that the vast majority of breaches involve exploiting known, unpatched vulnerabilities. In fact, one Ponemon Institute study found that 60% of breaches are traceable back to vulnerabilities. These numbers highlight the danger of overload: with so many CVEs out there and so few patches being applied, teams must be extremely selective.
Operationalizing CVE Data with Cymulate
CVE identifiers and CVSS scores offer a baseline for understanding vulnerabilities, but they don’t reflect how threats behave in real environments. Cymulate bridges this gap by continuously validating security controls through real-world attack simulations involving known CVEs, such as Log4Shell (CVE-2021-44228), to determine whether they can be exploited in your live environment.
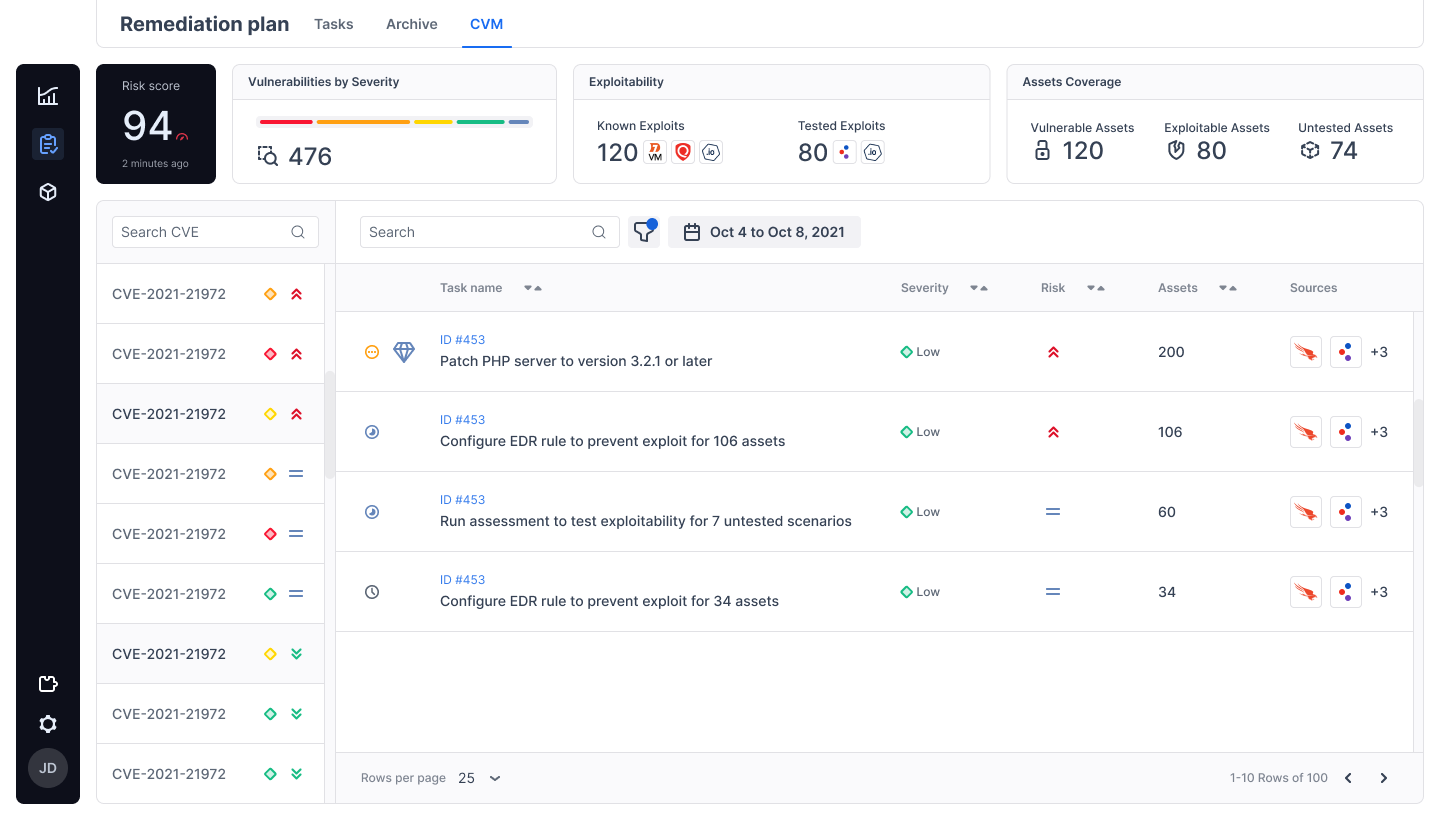
These simulations are mapped to the MITRE ATT&CK framework, showing which defenses detect or miss specific techniques and producing a detailed, evidence-based view of your organization's actual exposure.
The Cymulate platform offers an integrated approach to continuous exposure validation, turning raw CVE data into practical, context-aware security insights. It includes several core capabilities that go beyond traditional vulnerability scanning:
- Breach and Attack Simulation (BAS): Runs realistic, automated attack scenarios, including CVE exploits and MITRE ATT&CK techniques, to assess how an attacker would move through your environment. BAS tests whether your controls can detect or block these threats in real time.
- Automated Red Teaming (ART): Builds on BAS by simulating multi-stage attacks. It maps attack paths across your network, revealing how CVEs and misconfigurations could enable privilege escalation or lateral movement.
- Prioritized Remediation Plans: Based on these scores, Cymulate provides clear, actionable remediation steps, highlighting affected assets, required fixes, and even offering custom detection rules for future monitoring. All guidance is tied back to specific CVE IDs for traceability.
Cymulate doesn’t just report on which CVEs exist; it helps organizations determine which ones pose real risk now, and why. This enables security teams to shift from static CVSS ratings to dynamic, validated vulnerability prioritization, based on actual exposures in their own environment.
Why Prioritize Exploitable Vulnerabilities
A critical insight from the Cymulate approach is the distinction between vulnerabilities and exploitable vulnerabilities. Not every CVE poses an immediate threat. An exploitable vulnerability is one for which an attacker has a workable method (an exploit) to compromise the target in its current state. This concept lies at the core of why Cymulate focuses on risk-based prioritization.
Cymulate improves vulnerability management by simulating real-world attack scenarios to determine whether a CVE is actually exploitable in your current environment. If a vulnerability appears in your system but defenses like firewalls neutralize it during testing, it’s deprioritized. On the other hand, if the simulation confirms the CVE can still be exploited - especially on critical assets - it’s flagged as high-risk.
This process shifts vulnerability management from theoretical analysis to evidence-based validation. Rather than treating every CVE as equally urgent, Cymulate asks: “If an attacker used this CVE, would our defenses stop them?” Only those that fail the test and pose a real threat are prioritized for remediation.
Key benefits of this approach:
- Real-time attack validation turns CVE tracking into a proactive security drill.
- Risk is measured by verified exploitability and potential business disruption, not theoretical severity
- Resources are focused on fixing vulnerabilities that matter most, reducing wasted effort on already-neutralized threats.
Cymulate helps security teams cut through the noise of massive CVE lists and static severity scores, enabling smarter, context-driven vulnerability prioritization. With continuous testing and analyzing real exposure, organizations can confidently focus on threats that are both relevant and exploitable - achieving a far more effective risk posture.
Featured Resources
View More Resources
Exploitable Vulnerabilities: Prioritize What Poses Real Risk
Prioritize vulnerabilities based on real exploitability—not just CVSS scores—to reduce risk and noise.
Task Scheduler– New Vulnerabilities for schtasks.exe
Cymulate uncovers schtasks.exe flaws that allow privilege escalation and event-log overwriting.