

What is eBPF? The Hacker's New Power Tool for Linux

eBPF (extended Berkeley Packet Filter) is a powerful and flexible technology originally designed for packet filtering in the Linux kernel. Over time, it has evolved into a versatile framework that allows the execution of custom programs within the Linux kernel without changing the kernel source code or loading kernel modules.
eBPF expands on this concept by allowing user-space programs to hook into many other Linux subsystems supporting this technology. The eBPF program pre-defined hook can be attached to a system call, function entry/exit in kernel and user space, network event, and several other event base hook points.
The ability to hook onto different Linux subsystems (not just sockets) and run user-space programs in the kernel context without writing any kernel module or driver is what makes eBPF such a powerful technology.
How does eBPF work?
When hackers launch an attack, they face several challenges. One of these challenges is bypassing the organization’s defense systems without being caught. These defense systems include Network firewalls, WAF, EDR/XDR, etc.
Another challenge is maintaining persistence in an endpoint while evading detection by the user or the monitoring systems in place. To overcome these obstacles, hackers rely on a large arsenal of malicious techniques documented in MITRE ATT&CK once they become known.
For example, a hacker attempting to bypass defense and monitoring systems and make their intrusion attempt look legitimate on the target machine can use process injection and Defense Evasion techniques. Furthermore, to maintain a foothold on the breached endpoint, that hacker would use persistence techniques.
As security products keep getting better at mitigating these sophisticated techniques, hackers continuously investigate new technologies, system services, operating system internal subsystems, and more to create new methods that security products fail to catch. One such technology is eBPF – Extended Berkley Packet Filtering. This new technology in the Linux operating system is starting to get more and more popular.
General Architecture & Components of eBPF
When compiling the eBPF program into byte code using Clang or LLVM compilers and loading it to the kernel using the bpf system call, the program will get to the eBPF Verifier. The Verifier will perform (in kernel context – ring0) a series of tests to check that the eBPF has the required capabilities (see Required Privileges & Capabilities section) and that the program is safe to be loaded and will not crash or hang the system.
After the Verifier approves that the program is permitted and safe to be loaded, it will continue to the eBPF JIT (Just in Time) compiler. The eBPF JIT compiler will translate the program’s byte code into machine code and attach it to the correct kernel hook points. This is the general flow of compiling and loading an eBPF program.
Another important component in this architecture is eBPF maps. eBPF maps are key-value pairs generic storage. They can be used for sharing data between kernel and user-space or between multiple eBPF programs. In addition, they can help in storing information in the same program. The maps have different types: hash, array, stack trace, ring-buffer, etc.
Portability
One of the many issues the eBPF community had to face is the portability of eBPF programs between different systems.
Using kernel data structures and types requires having access to the system kernel debug information. In the past, this was typically done by installing the corresponding version kernel headers. The dependence on kernel headers was very problematic when attempting to run an eBPF program on different targets. It was solved by developing BTF (BPF type format) and CO-RE (Compile once run everywhere).
BTF is the metadata format that encodes the debug information related to the BPF program/map. This metadata includes the kernel data structures and types. It’s a minimalistic, compact format that encapsulates all data needed by bpf programs into the Linux kernel.
CO-RE – BPF Compile-Once Run-Everywhere is a relatively new approach in the eBPF world for compiling eBPF modules only once. While BTF allows capturing crucial information about kernel types and data structures, CO-RE records which parts of a BPF program need to be rewritten and how, so that the bpf program will be compatible with any kernel version (as long as the kernel contains BTF information).
The combination of BTF and CO-RE solves the portability issue. The only prerequisite is that the target kernel has to be built with config option set to CONFIG_DEBUG_INFO_BTF=y.
Required Privileges & Capabilities
Loading an eBPF program into the kernel requires specific permissions. In the past, loading it required full root permissions or CAP_SYS_ADMIN capability. Today, in the effort to allow loading these programs without the CAP_SYS_ADMIN capability (for robustness reasons), CAP_BPF is used. Adding other capabilities, such as CAP_PERFMON or CAP_NET_ADMIN, will enhance the eBPF program capabilities on the system.

https://elixir.bootlin.com/linux/v5.0.21/source/include/uapi/linux/capability.h
There are some exceptions in the context of loading an eBPF program. Programs of type BPF_PROG_TYPE_SOCKET_FILTER can be loaded by an unprivileged user. This type of program enables very limited filtering functionality on a socket. The only way to block unprivileged users from loading any type of eBPF program is by setting the value of /proc/sys/kernel/unprivileged_bpf_disabled to 1 or 2:
- When set to 1, unprivileged eBPF is disabled. A system reboot is needed to enable it after changing this value.
- When set to 2, unprivileged eBPF is disabled. A system reboot is not needed to enable it after changing this value.
Where is eBPF used?
The number of eBPF-based projects has exploded in recent years, and many more have been announcing an intent to start adopting the technology. Small startups started creating new products based on this technology, and enterprises started using it for various use cases. eBPF-based programs are useful primarily in four fields: Networking, Profiling, Observability, and Security.
1. Networking
The Linux kernel TC (traffic control) and the XDP (eXpress Data Path) eBPF infrastructures can be used for processing packets or even row packets buffer at different hook points in the network stack and performing various operations on them.
This functionality helps in several ways. For example:
- reading and writing into packets metadata
- changing network paths by bypassing complex routing
- receiving or dropping row packet buffers as they enter the system
- deciding on network policies
- providing high-performance networking and load-balancing in modern data centers or cloud-native environments
Many companies use these abilities. Facebook, for instance, uses Katran (a C++ library and eBPF program) to build a high-performance layer 4 load-balancing forwarding plane. Katran leverages the XDP infrastructure to provide an in-kernel facility for fast packet processing. On the other hand, Cloudflare uses L4Drop, a packet-dropping tool, as part of their denial of service (DDoS) attack mitigations. This tool also uses the XDP infrastructure.
2. Profiling
Profiling and tracing have been a key part of the software development cycle for many years. The ability to attach eBPF programs to trace points as well as kernel and user functions allows unprecedented visibility into the runtime behavior of applications and the system itself. This ability can help developers trace their applications or even troubleshoot system performances by performing analytics on data they extract from the kernel.
One of the best-known tools in that area is bpftrace. bpftrace is a high-level tracing language for Linux eBPF that analyzes production performance problems and troubleshoots. There are other tool options, some even capable of tracing and profiling cloud native environments without the danger of crashing the host (node) and with low overhead.
3. Observability
When managing a Kubernetes environment that includes multiple pods, nodes, and even clusters, getting full visibility without manual instrumentation is almost impossible. eBPF solves that problem.
Enabling data collection from hosts (kernels) using event base mechanisms like Kprobes and Uprobes provides a deep understanding of the Kubernetes environment process flows. This can be very helpful in streamlining organizational processes and solving problems in development or production environments.
Today this observability field has become very relevant as organization environments and SaaS products start to run on cloud native environments in general and on Kubernetes framework, to be more specific. This is why we begin to see more solutions like Cilium (Hubble) or Pixie, which gives high- and low-level views at node level, cluster level, or even across clusters in a multi-cluster scenario.
4. Security
Security is another aspect where eBPF programs can help. Using eBPF to consume system events from a PC or the cloud-native stack can catch malicious behaviors and stop them on runtime. All of this is possible using the ability of eBPF programs to hook into system calls, the network stack, and different kernel and user functions. Falco and Tracee, for example, are cloud-native runtime security tools that detect and alert on suspicious behaviors.
To summarize, eBPF technology facilitates many development cycle stages, enables different networking capabilities, and improves security. This is where we switch hats and start thinking about how this technology can help hackers expand their arsenal of malicious techniques.
How Hackers Use eBPF
One malicious use of eBPF technology is looking for vulnerabilities in the mechanism itself. For example, a malicious actor could target the eBPF verifier that validates eBPF programs in kernel context. If a vulnerability is found and the hacker can execute unauthorized code using this vulnerability in the kernel, this could lead to a Privilege Escalation scenario (ZDI-20-1440). Other logical problems or advanced manipulations might lead to container escapes (CVE-2021-31440) or sandbox escapes (Issue 1320051).
Another approach is to use eBPF programs to install a rootkit on a victim machine. The rootkit might use the XDP and TC infrastructures to manipulate ingress and communications or extract sensitive data from the network. It can also hide itself and achieve persistence using different hook points, elevate process privileges and even create backdoors to maintain its foothold.
In this blog, we focus on one scenario: using an eBPF rootkit and hiding malicious processes from “ps” like programs by hooking into the getdents64 system call through the tracepoint subsystem.
When hooking using tracepoints, it is possible to hook into a system call procedure entry and exit points. This example uses both options.


It is important to know that using a tracepoint hook point in an entry of a system call enables accessing all the system call parameters. However, hooking to the exit of a system call only gets the return value without access to their ascribed parameters.
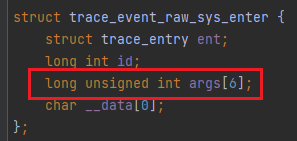
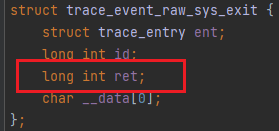
After talking about the tracepoint subsystems and their characteristics, time to look at the getdents64 system call used to hide the malicious process.
https://elixir.bootlin.com/linux/v5.19.12/source/include/linux/syscalls.h
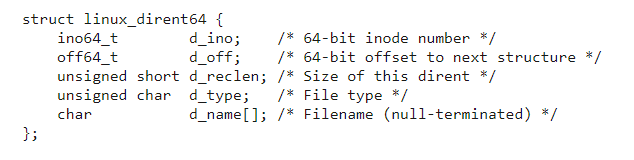
https://man7.org/linux/man-pages/man2/getdents.2.html
This system call reads linux_dirent64 structures of the directory file descriptor that was passed through the fd parameter. If this system call runs successfully, it returns an array filled with linux_dirent64 structured data in a user-space buffer pointed by dirent.
The two key fields in the linux_dirent64 structure require close attention:
- d_name à The name of the file/directory that the directory entry struct refers to.
- d_reclen à The size of the linux_dirent64 struct. d_reclen field enables functions like readdir (calls sys_getdents64 internally) to run over all the directory entries in the array buffer pointed by dirent without accidentally skipping or corrupting an item in it.
Skipping... well... This is where a hacker can intervene. Using the bpf-helpers function bpf_probe_write_user, the hacker can manipulate the dirent buffer (located in user space). This enables the hacker to make readdir “accidently” skip one entry in the /proc directory, which, surprisingly, would be the malicious process.
These are the steps used to achieve that goal:
1. Save the dirent pointer for every process that calls getdents64 in an eBPF hash map. This is done when entering the system call, because it is the point where granting access to the system call parameters.

2. When getting to the sys_getdent64 exit hook point, look for the dirent pointer saved in the hash map.

3. At this point (the exit of the system call), the dirent buffer already contains data. In other words, the dirent_pointer is pointing to an actual array filled with linux_dirent64 structures. If the directory iterating over its entries is the /proc directory, the hacker must search for the malicious process directory and remove it. The search will be performed using the eBPF bpf_probe_read_user and bpf_probe_read_user_str helper functions.
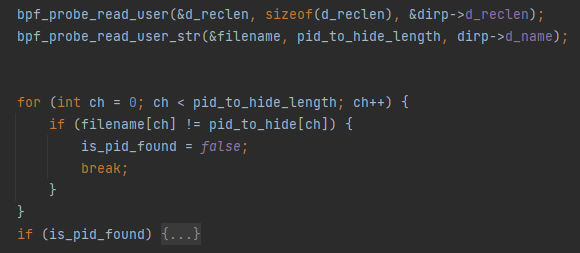
4. “Removing” the malicious process is done by changing the prior linux_dirent64->d_reclen field to the size of itself combined with the size of the malicious process d_reclen field. This is done by using bpf_probe_write_user As a result, when reading the dirent buffer, the malicious process linux_dirent64 structure will be skipped.

Key Takeaways
To sum up, eBPF technology entered our lives by storm in a variety of areas, some of which are mentioned in this article. Cymulate research team sees the positive side of this technology, but also for its potential for use by malicious actors. The best way to ensure that your environment is safe from this type of attack is to emulate them - and Cymulate does just that ?.

Featured Resources
View More Resources
Cymulate Exposure Validation
Prove security readiness with AI-powered exposure validation that continuously tests threats and strengthens defenses.

How cybersecurity leaders are optimizing their budgets in 2025
2024 was a year that saw some of the biggest and most damaging data breaches in recent history, according to